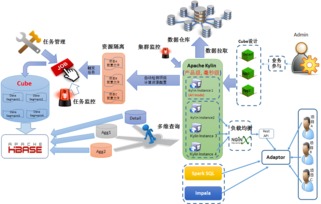
在地图服务领域,数据处理面临着海量、多维、实时的挑战。Apache Kylin作为一个开源的分布式分析引擎,为地图工程师提供了一套强大的OLAP(在线分析处理)解决方案,使其能够高效地处理和分析庞大的地理空间数据。以下是地图工程师利用Apache Kylin处理数据、构建数据处理服务的关键实践方式。
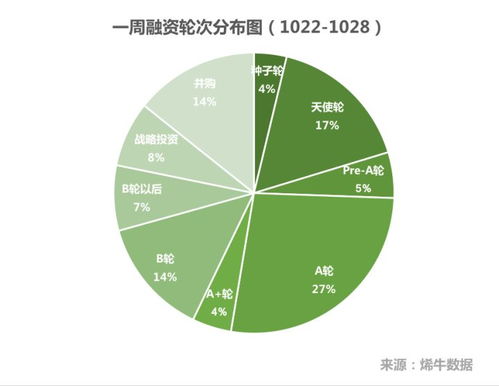
一、构建多维数据立方体,加速空间查询分析
地图数据天然具备多维特性,如时间、区域、POI类型、交通流量等。工程师利用Kylin的预计算能力,将这些维度与度量(如访问量、停留时长、路径规划次数)结合,预先构建数据立方体(Cube)。当用户进行复杂的地图分析查询(例如“2023年Q3北京市朝阳区餐饮类POI的访问热力趋势”)时,系统无需扫描原始TB/PB级数据,而是直接从Cube中亚秒级返回结果,极大提升了交互式分析的体验。
二、集成空间数据与业务数据,实现统一数据服务
地图服务不仅需要基础地理信息,还需整合来自用户行为、商户信息、物流轨迹等业务数据。工程师通过Kylin将Hadoop/Hive中的原始空间数据与业务数据表进行关联建模,在Cube定义中创建星型或雪花型模型。这使得数据处理服务能够一站式提供融合了地理位置与业务指标的聚合数据,例如“实时区域人流密度与周边商户促销活动的关联分析报告”。
三、支撑实时与近实时地图数据更新
对于交通路况、即时配送等场景,数据需要近实时更新。Kylin支持从Kafka等流数据源构建准实时Cube。地图工程师可以配置流式数据接入,实现分钟级甚至秒级的数据刷新。这样,数据处理服务能持续产出最新的拥堵指数、预计送达时间等动态指标,为导航推荐和调度决策提供即时依据。
四、优化地理网格聚合计算
在处理大规模地图数据时,常需按地理网格(如Geohash或自定义网格)进行区域聚合。工程师在Kylin的Cube设计中,将地理坐标转化为网格编码作为维度,并预计算各网格的聚合值(如网格内车辆总数、平均速度)。这避免了查询时昂贵的实时地理空间计算,让“查看城市各区域实时车流分布”等查询变得快速而轻量。
五、保障高并发地图API数据供给
地图应用后端通常需要向众多终端提供稳定的数据API服务。Kylin的高并发查询能力与低延迟特性,使其非常适合作为数据服务层。工程师将Kylin与微服务架构结合,通过REST API或JDBC/ODBC驱动,向地图渲染引擎、路径规划服务、数据分析平台等输出已处理的聚合数据,确保了前端应用流畅的数据获取体验。
六、实现成本与性能的平衡
地图数据量增长迅猛,存储与计算成本控制至关重要。Kylin的智能剪枝、分层构建等功能,让工程师能根据数据热度设计不同的Cube刷新策略(如全量/增量构建),并对历史冷数据采用归档存储。这样,数据处理服务在保证热点数据高效查询的显著降低了整体基础设施开销。
Apache Kylin通过其强大的预计算、多维分析与高并发支持能力,已成为地图工程师处理海量空间数据的核心工具之一。它赋能团队构建出响应迅速、稳定可靠的数据处理服务,从而支撑起从日常导航到城市智慧大脑等各类复杂地图应用场景,让数据背后的地理洞察触手可及。